Privacy and Confidentiality Concerns of Large Language Models [Resource]
C. Anneke Snyder
What You Will Learn in This Section
In this section, you will gain insights about privacy and confidentiality concerns related to a form of Generative Artificial Intelligence (GenAI) known as Large Language Models (LLMs) and, specifically, OpenAI’s policies about ChatGPT.
The full extent of privacy and confidentiality risks in relation to ChatGPT, which relies on collective intelligence for information gathering and dissemination, has not been fully realized. Users should be mindful of OpenAI’s terms of use, particularly as those terms are subject to change. Though OpenAI claims to not share private user information, the language around such statements is vague and contradictory, and there is a strong possibility that personal information may be monitored by human proctors. Moreover, educators who are bound to the legal obligations outlined in FERPA should be particularly concerned about how student privacy could be potentially violated by using ChatGPT and other GenAI technologies.
After reading this section, you should be able to articulate and discuss OpenAI’s significant terms of use and privacy policy, consider the potential privacy and intellectual property violations contained within the collective intelligence paradigm, and communicate your own concerns about privacy and confidentiality in relation to GenAI technologies.
This chapter is divided in the following sections. Click the links below to jump down to a section that interests you:
- Author Reflection: How has my understanding of AI evolved?
- Why are privacy and confidentiality important concerns in the era of generative AI?
- What essential information is contained within OpenAI’s terms of use for ChatGPT?
- What are the consequences of individual information becoming part of the collective?
- What are other privacy and confidentiality concerns for educators?
- Why should educators share privacy and confidentiality concerns with students?
- What privacy and confidentiality concerns should educators share with students?
Author Reflection: How has my understanding of AI evolved?

Like most people confronted with new technology, I went through different emotional stages, not unlike the stages of grief, when faced with GenAI: denial that this technology existed, apprehension as I accepted that this technology was here to stay, anticipation as I used this technology for the first time, and excitement as I began to realize the possibilities of using such a tool. All of these thoughts brought me to my current stage of thoughtful contemplation. My use of ChatGPT and other forms of GenAI began when I started working on this project which was, coincidentally, a time when I was also actively writing one of my dissertation chapters. As I worked on my dissertation, I found myself using ChatGPT as a thesaurus, dictionary, translator, editor, and a host of other resources; I could input my messy, inarticulate thoughts and receive lucid and concise iterations of what I wanted to say. However, the more I learn about collective intelligence and the imprecision of GenAI’s intellectual property protections, the more reluctant I am to input my original ideas, work, and research into ChatGPT. While I still use ChatGPT to find a word that I can’t remember, to finish a sentence that I’m not sure how to end, and to suggest wording on a particular topic, this work is superficial in nature. I want to protect my own nuanced ways of thinking and writing as a human being and an academic. Yet, I can also envision a world in the very near future where I will move on from thoughtful contemplation to a stage of active and eager engagement with ChatGPT and other forms of GenAI as I modify and adapt my own research and writing practices to the evolving world in which we live.
C. Anneke Snyder (see fig. 1) is a Ph.D. candidate whose work focuses on Latinx, multiethnic, and transnational literatures in the Department of English at Texas A&M University.
Why are privacy and confidentiality important concerns in the era of generative AI?
Because of the Unknown Implications
Safeguarding privacy requires particular attention and vigilance within the context of Large Language Models (LLMs). Specifically, educators should be concerned with issues of student confidentiality and individual institutional constraints regarding this Generative Artificial Intelligence (GenAI) technology. While LLMs are themselves not recent innovations, the granting of public access to ChatGPT in November 2022 has potential ramifications that are not fully realized. ChatGPT itself generates warning against ramifications like “data breaches” and “unauthorized access” when asked what a user should be concerned about in terms of privacy and confidentiality (see fig. 2).[1]
By studying and analyzing OpenAI’s terms of use and means of data collection for ChatGPT, educators can gain a better understanding of an LLM’s capabilities and restrictions relating to privacy and confidentiality. Additionally, looking into pertinent educational concerns and matters related to LLMs can give educators further insight into the implications of using this online tool.
Note: Screen-readable Word version of ChatGPT’s response regarding privacy and confidentiality.

What essential information is contained within OpenAI’s terms of use for ChatGPT?[2]
Note: Screen-readable Word version of OpenAI’s overview of terms of use.
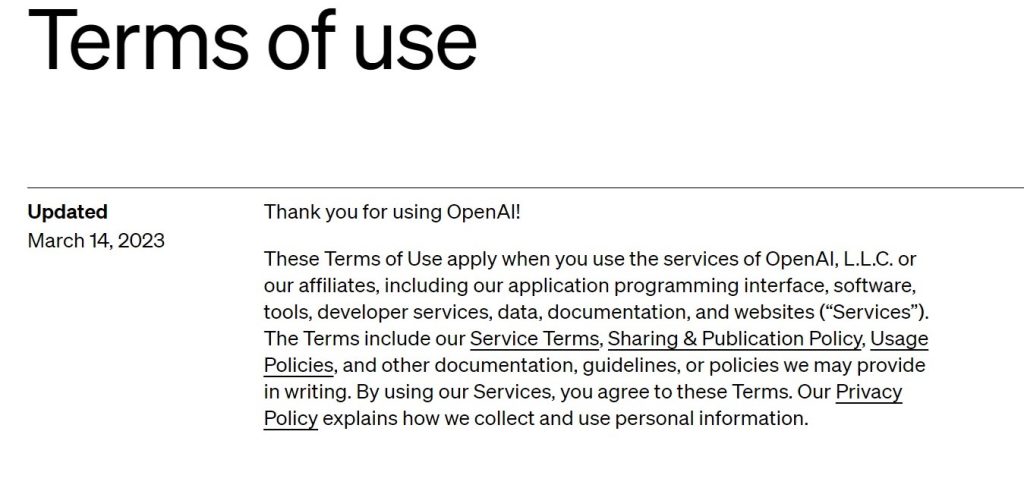
Privacy & Confidentiality are Not Guaranteed
Open AI’s terms of use for ChatGPT regulate the amassment and compilation of user data, including any personal information. Though restrictions have been placed around use of this LLM, such safeguards do not ensure privacy and confidentiality. Indeed, fig. 3[3] features OpenAI’s updated terms of use (Mar 14, 2023), which includes a reference to how they collect and use personal data in their Privacy Policy.
OpenAI organizes terms of use into nine categories:
- Registration and Access
- Usage Requirements
- Content
- Fees and Payments
- Confidentiality, Security, and Data Protection
- Term and Termination
- Indemnification; Disclaimer of Warranties; Limitations of Liability
- Dispute Resolution
- General Terms
In this section, we highlight the terms, policies, rules, and regulations that are most applicable and relevant to educators. We do not include or review all terms, policies, and conditions contained within the terms of use.
Terms May Be Amended
It is critical for users to remember that OpenAI’s terms of use state that OpenAI may amend the terms by posting an update on their website. If a change has the potential to adversely impact a user, the user will receive an email notification, and the changes will take effect within thirty days. Moreover, continued use of ChatGPT’s services after these changes have taken place means that the user agrees to such changes.
Some Terms Have Significant Implications
We define significant terms of use to include information about which all users, and particularly educators, should be aware before engaging with ChatGPT. Unfamiliarity with these policies can lead to unintended non-compliance, confusion, or negative repercussions. Educators should be particularly cognizant of restrictions and expectations contained within the terms of use before allowing or encouraging students to engage with this technology.
Age Restrictions
- Users must be at least 13 years of age.
- Users under 18 must have parent/guardian permission to use the technology.
User Expectations
- Users Will:
- comply with any rate limits and other requirements in OpenAI’s documentation
- use services only in geographies currently supported by OpenAI
- Users Will Not:
- utilize ChatGPT in a way that infringes, misappropriates or violates any person’s rights
- create more than one account to benefit from credits provided in the free tier of the services
- reverse assemble, reverse compile, decompile, translate or otherwise attempt to discover the source code or underlying components of models, algorithms, and systems of the services
- use output from the services to develop models that compete with OpenAI
- except as permitted through the API, use any automated or programmatic method to extract data or output from the services, including scraping, web harvesting, or web data extraction[4]
- represent that output from the services was human-generated when it is not or otherwise violates Open AI’s usage policies
- buy, sell, or transfer API keys without OpenAI’s prior consent
- send OpenAI any personal information of children under 13 or the applicable age of digital consent
Legal Constraints
- Any third-party software, services, or other products a user uses in connection with the services are subject to their own terms, and OpenAI is not responsible for third party products.
- OpenAI and the user are independent contractors and neither party will have the power to bind the other or to incur obligations on the other’s behalf without the other party’s prior written consent.
- These terms will be governed by the laws of the State of California, excluding California’s conflicts of law, rules, or principles. Except as provided in the “Dispute Resolution” section of the terms of use, all claims arising out of or relating to these Terms will be brought exclusively in the federal or state courts of San Francisco County, California, USA.
Disclaimers
- Services are provided “as is.” Except to the extent prohibited by law, OpenAI and its affiliates and licensors make no warranties (express, implied, statutory or otherwise) with respect to the services, and disclaim all warranties. OpenAI does not warrant that the services will be uninterrupted, accurate or error free, or that any content will be secure or not lost or altered.
- Neither OpenAI nor any of its affiliates or licensors will be liable for any indirect, incidental, special, consequential or exemplary damages, including damages for loss of profits, goodwill, use, or data or other losses, even if OpenAI has been advised of the possibility of such damages.
Caveats to Confidentiality Exist
Protections and limits of confidentiality are outlined in OpenAI’s terms of use. However, there are constraints to this confidentiality, and the wording contained within these terms should be closely examined for potential breaches, evasions, vulnerabilities, and oversights (see table 1).
In the company’s terms of use, OpenAI defines confidential information as “nonpublic information that OpenAI or its affiliates or third parties designate as confidential or should reasonably be considered confidential under the circumstances, including software, specifications, and other business information” (para. 17).[5]
Table 1
OpenAI’s Definitions of Non-Confidential Information
OpenAI defines non-confidential information as information that is contained within the following parameters:
- Information that is or becomes generally available to the public through no fault of the user.
- Information which a user already possesses without any confidentiality obligations.
- Information that is rightfully disclosed to a user by a third-party without any confidentiality obligations.
- Information independently user-developed without using confidential information.
Users are encouraged to protect their confidential information in accordance with common practices. However, beyond this suggestion, which is itself vague, guidance on the protection of confidential information is imprecise and nebulous.
In addition to OpenAI’s terms of use, the data usage for consumer services FAQ states that user information may be viewed by OpenAI and shared with third party contractors of both digital and human origin. Though this information is shared on a need-to-know basis, details on what is essential and what is excessive remain unclear.
What are the consequences of individual information becoming part of the collective?
“Now you see your data, now you don’t. Meanwhile your precious data has become part of the collective, as it were.”
–Lance Eliot, “Generative AI ChatGPT Can Disturbingly Gobble Up Your Private And Confidential Data, Forewarns AI Ethics And AI Law” in Forbes (Jan. 2023) [6]
Data is Amassed in the Collective
At the center of concerns about the limits to confidentiality of ChatGPT are apprehensions about personal privacy and the ownership of intellectual property. Moreover, because millions of users worldwide utilize ChatGPT, the scale of collaboration between human and machine is unprecedented. Ultimately, questions, phrases, and expressions input into ChatGPT influence output, and together, this combination is colloquially termed “the collective.”
The collective, also known as collective intelligence, refers to the amassment of data by LLMs through user engagement. Because ChatGPT has the ability to improve responses based on user application, awareness of how that data is mined is a critical component of understanding the ownership of ideas.
Intellectual Property Becomes Content
Section 3, “Content” in OpenAI’s terms of use address basic concerns regarding intellectual property. Content refers to the collective of user input and generative AI output (see fig. 4).[7] The terms of use state that a user owns input while Open AI also assigns the company’s rights to output to the user so that a user can use Content for any purpose, including a commercial one.[8] However, OpenAI cannot simultaneously guarantee both the uniqueness and consistency of output (see figs. 4 & 5). Furthermore, not all forms of input are protected by intellectual property laws.
OpenAI illustrates this point with an example about how asking a model a question like “What color is the sky”? may receive output such as “the sky is blue” (see fig. 5).[9] Yet, a different user at a different time might ask ChatGPT that same question, and receive a different answer, as seen in Fig. 5 where ChatGPT describes how “the color of sky can vary depending on various factors.”
Example 1: What color is the sky?
Note: Screen-readable Word version of Example 1 (What color is the sky).

Example 2: What color is the sky?
Note: Screen-readable Word version of Example 2 (What color is the sky).

While OpenAI designates rights to Content, ownership and protections of input and output is often beyond the company’s scope and jurisdiction. Though OpenAI assigns its rights to output to the user, the company does not necessarily have initial ownership of this output in the first place. Moreover, because ChatGPT retains a record of user history, that history can become a part of the training program for the language model and input can be disseminated (see the Samsung ban of ChatGPT for more information).
Despite OpenAI’s attempt to delineate intellectual property rights, the ambiguity surrounding the information mined and generated by LLMs does not allow for such clear-cut specificity or assurance to users.
Personal Privacy is Not Secure
OpenAI’s privacy policy outlines and governs the dissemination of personal information. Personal information is gathered through account information, user content, communication information, and social media interaction (see table 2). However, of these four, user content has the most ambiguous implications and consequences.[10]
User content is used to train LLMs like ChatGPT. Though OpenAI claims that this training information is to help models understand and respond to language, users have little knowledge and no control over what information they provide is used for these training purposes. Moreover, OpenAI’s privacy policy states that personal information is not utilized in this training. Yet, this same policy indicates that if personal information is input or requested multiple times, it may become part of the training program and then available for general user consumption.
Table 2
OpenAI’s Uses of Personal User Information
Overall, OpenAI may use personal information to conduct the following according to the privacy policy:
- provide, administer, maintain, and/or analyze services
- improve services and conduct research
- communicate with users
- develop new programs and services
- prevent fraud, criminal activity, or misuses of services
- protect the security of OpenAI’s IT systems, architecture, and networks
- carry out business transfers
- comply with legal obligations and legal process and to protect OpenAI’s rights, privacy, safety, or property, and/or that of OpenAI’s affiliates, users, or other third parties
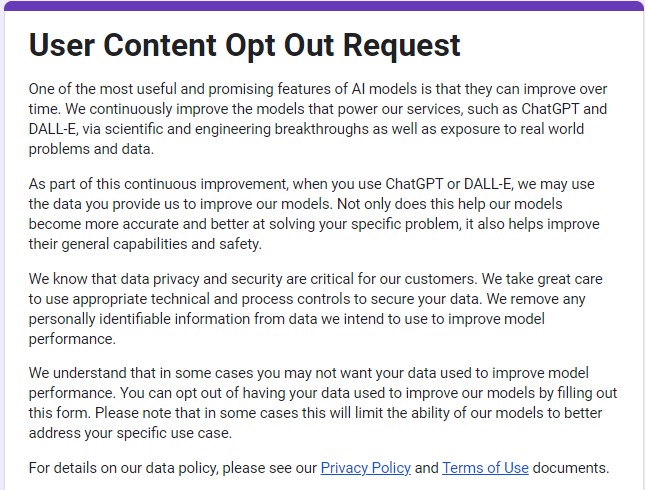
Users who have concerns about privacy can request their personal information be removed from OpenAI’s training through either filling out the OpenAI Personal Data Removal Request form or through the User Content Opt Out Request form (see fig. 6).[11] A data deletion request, which potentially involves deleting a personal OpenAI account, is an option for users who want to more permanently remove their information. However, there remains a possibility that OpenAI will refuse these requests.
More information about privacy and security can be found on this page.
Note: Screen-readable Word version of the User Content Opt Out Request.
What are other privacy and confidentiality concerns for educators?
Protection and Data Security of Students
Beyond awareness of their own personal privacy and confidentiality, educators should also consider the information protection and data security of their students. Because of the data mining and collective intelligence involved in the creation and maintenance of LLMs, educators should set clear and transparent data and technology expectations for their students in order to preemptively safeguard their data security (see table 3). Moreover, educators should also keep in mind policies surrounding AI that have been set in place by their institutions, cities, states, and other governing bodies. These policies may prevent instructors from independently inputting their students’ work into an LLM like ChatGPT for evaluative purposes.
Table 3
Considerations for Educators Before Including LLMs in their Courses
We suggest that educators consider privacy and confidentiality concerns associated with LLMs, such as ChatGPT, before allowing such technology into their classrooms.
- Requiring that students create accounts to utilize LLMs, such as ChatGPT, in the classroom may infringe on a student’s rights to privacy and confidentiality.
- Using LLMs, such as ChatGPT, may infringe upon privacy and confidentiality as defined by FERPA.
- Providing a syllabus statement or clarifying classroom policies can help outline individual educator expectations for students when it comes to LLMs such as ChatGPT.
- Consulting with an ethics committee or similar institutional body on potential infringement of student privacy and confidentiality when incorporating LLMs and other forms of generative AI into the classroom may help clarify the ethical implications and ensure responsible use of these technologies.
Why should educators share privacy and confidentiality concerns with students?
Students Should Make Informed, Consensual Decisions
Privacy and confidentiality are concerns for students as well as educators. If students are unaware of how their personal information, ideas, and content will be utilized within LLMs, and specifically ChatGPT, they may find that their privacy and confidentiality has been unknowingly violated without their consent. Informing students of privacy and confidentiality concerns allows them to make a more informed, consensual decision to the terms of use, privacy policy, and other policies regulated by OpenAI.
What privacy and confidentiality concerns should educators share with students?
Educators can use the language in table 4 to share an abbreviated version of this section with students.
Table 4
Considerations of Privacy and Confidentiality Concerns About LLMs to Share with Students
Before using Generative Artificial Intelligence (GenAI), you should consider your own sense of privacy, confidentiality, security, and the safety concerns related to these issues.
Large Language Models (LLMs), such as ChatGPT, do not always protect your private information and might even use such information for training purposes. Because your information becomes part of what is known as collective intelligence, any questions, phrases, expressions, ideas, or information you input into ChatGPT becomes part of the LLMs’ learning source. Furthermore, ownership of intellectual property within the collective is ambiguous; the information that you personally input while using an LLM can be legally indistinguishable from the information generated by the AI technology.
Finally, you should consider the policies around large language models in general, and ChatGPT in particular, when it comes to your institution’s regulations, your understanding of privacy, and your instructor’s expectations.
You should read OpenAI’s terms of use and privacy policy for more information before making a decision on whether or not to use ChatGPT.
Attribution:
Synder, C. Anneke. “Privacy and Confidentiality Concerns of Large Language Models [Resource].” Strategies, Skills and Models for Student Success in Writing and Reading Comprehension. College Station: Texas A&M University, 2024. This work is licensed with a Creative Commons Attribution 4.0 International License (CC BY 4.0).
Images and screenshots are subject to their respective terms and conditions.
- ChatGPT, response to “Why should a user be concerned about privacy and confidentiality when using ChatGPT?,” June 2023, OpenAI, https://chat.openai.com. ↵
- This is not an exhaustive overview of OpenAI’s terms of use. Rather, this section of the module functions as an overview highlighting what we believe to be the most relevant points for educators. We encourage educators to read OpenAI’s terms of use in full. ↵
- OpenAI, "Overview of Terms of Use," OpenAI, March 14, 2023, https://openai.com/policies/terms-of-use. ↵
- API stands for Application Programming Interface which, at a basic and fundamental level, provides a developer with access and written instructions for accessing the backend of a system. ↵
- Open AI. “Terms of use.” https://openai.com/policies/terms-of-use. Accessed 3 July 2023. ↵
- Eliot, Lance. “Generative AI ChatGPT Can Disturbingly Gobble Up Your Private And Confidential Data, Forewarns AI Ethics And AI Law.” Forbes. 27 Jan. 2023. https://www.forbes.com/sites/lanceeliot/2023/01/27/generative-ai-chatgpt-can-disturbingly-gobble-up-your-private-and-confidential-data-forewarns-ai-ethics-and-ai-law/?sh=594a38b37fdb. Accessed 3 July 2023. ↵
- Open AI. “Terms of use.” https://openai.com/policies/terms-of-use. Accessed 3 July 2023. ↵
- When the word content is capitalized as Content, the term refers to the combination of input and output. ↵
- ChatGPT, response to “What color is the sky?,” June 2023, OpenAI, https://chat.openai.com. ↵
- Open AI. “Privacy policy.” https://openai.com/policies/privacy-policy. Accessed 3 July 2023. ↵
- OpenAI, "User Content Opt Out Request," accessed June 29, 2023. ↵
